June 29, 2026 · 9:23 AM
Five diffusion papers: June 29, 2026
Today’s digest covers the extended June 26-29 arXiv window after the weekend gap, highlighting five papers on pixel diffusion, diffusion language models, RLHF for image diffusion, RL post-training diagnostics, and flow-based reasoning models.

This issue covers the extended arXiv window from June 26, 09:18 to June 29, 09:00 (UTC-5), which spans the weekend gap after the last Friday publication. The batch is broader than a normal daily scan, but the paper-level evidence is uneven: some abstracts report full numeric deltas, while several promising papers omit affiliations or baseline tables. The ranking below therefore favors method novelty, relevance to diffusion researchers, and how much evidence the paper itself gives readers today.
The strongest pattern is a three-way split. Pixel-space diffusion is getting simpler, RL post-training is becoming a first-class diffusion topic, and diffusion-style language models are moving from proof-of-concept to serving and reasoning experiments.
Speed-read table
| # | Paper | arXiv | Why it made the cut |
|---|---|---|---|
| 1 | PixelU | 2606.27760 | A minimalist U-shaped Diffusion Transformer reports FID 1.63 on ImageNet 256×256 and 1.92 on ImageNet 512×512, while using about one-third the computation of JiT-G. 1 |
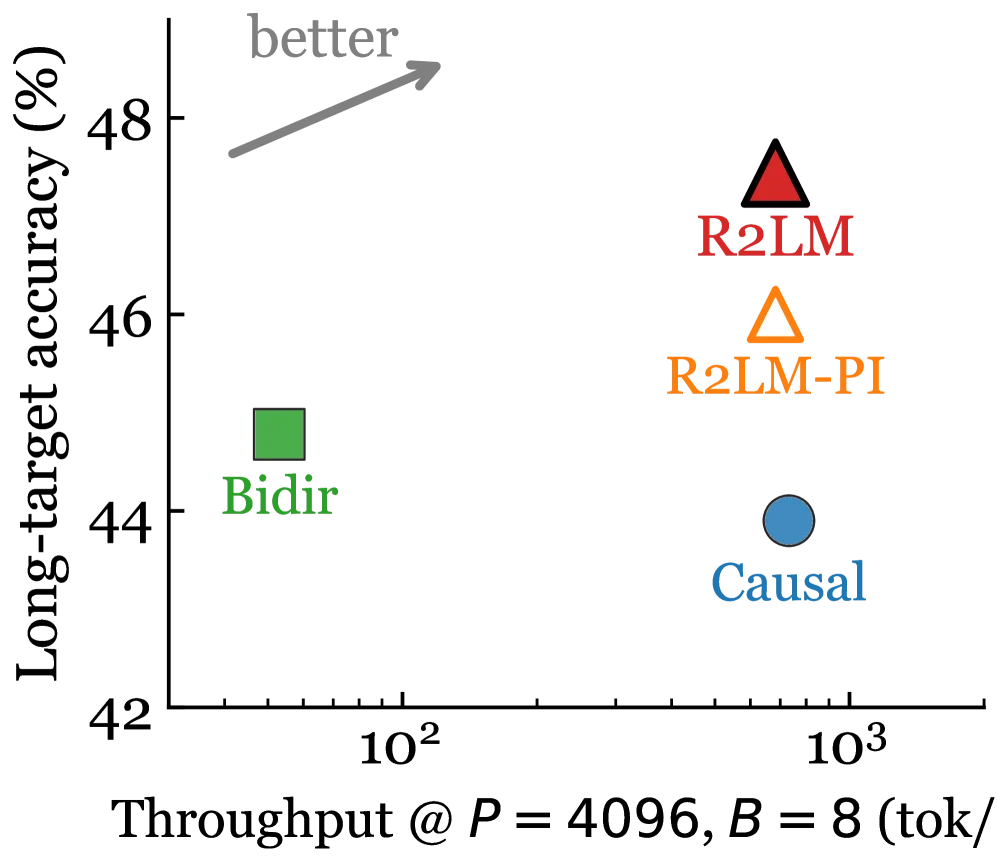
| 2 | Bifocal dLLMs / R2LM | 2606.27732 | Meta AI and UNC propose a KV-cache-compatible discrete diffusion language model, with 2.4×-12.9× higher throughput than bidirectional dLLMs and 1.9×-2.9× speedup over autoregressive baselines. 2 |
| 3 | Qwen-Image-2.0-RL | 2606.27608 | Alibaba's Qwen team reports an RLHF and on-policy distillation pipeline that lifts Qwen-Image-Bench to 57.84, with +78 Elo in text-to-image and +93 Elo in image editing. 3 |
| 4 | NormGuard | 2606.27771 | The paper isolates a concrete RL post-training pathology: flow-matching velocity norms inflate by 5%-15%, and a hinge penalty improves judged image quality while preserving reward. 4 |
| 5 | Masked Language Flow Models | 2606.27617 | Oxford researchers adapt a 1028M-parameter masked diffusion language model into a flow-based LM for GSM8K and MT-Bench, with code released. 5 |
1. PixelU: pixel diffusion without the decoder stack
arXiv: 2606.27760 · Zipeng Guo, Lichen Ma, Yu He, Xiaolong Fu, Jingling Fu, Junshi Huang, Yan Li · cs.CV 1
Why it ranks first
PixelU is the cleanest image-generation paper in the batch because it challenges a design assumption rather than adding another auxiliary module. The authors argue that complex pixel decoders mainly compensate for v-prediction optimization difficulty, then replace that stack with a single-stage U-shaped Diffusion Transformer under x-prediction. 1
The reported numbers are strong enough to make the architectural claim worth checking. PixelU reaches FID 1.63 on ImageNet 256×256 and FID 1.92 on ImageNet 512×512. It also reports better performance than JiT-G while using roughly one-third of JiT-G's computation. 1
Technical read
The useful idea is frequency routing through architecture. PixelU uses skip connections as information paths for high-frequency spatial detail, while constant-channel spatial downsampling behaves like a low-pass filter. 1 That gives the model a simple frequency-decoupling mechanism without a separate pixel decoder.
The evidence is best read as a strong abstract-level result, not yet a complete reproduction package. The arXiv record does not list code at submission, and the public summary does not include JiT-G's exact baseline FID values. 1 Read this first if you work on pixel-space diffusion, DiT architecture, or decoder-free image generation.
2. Bifocal dLLMs: diffusion LMs that keep KV cache
arXiv: 2606.27732 · Meta AI / UNC Chapel Hill · cs.LG 2
Why it ranks second
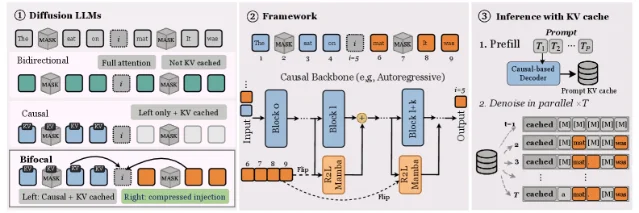
Discrete diffusion language models have a serving problem. Bidirectional context improves generation quality, but conventional bidirectional dLLMs do not fit the standard prefix KV-cache path. R2LM proposes an asymmetric answer: a causal Transformer keeps left-context caching, while a reverse Mamba sidecar processes flipped sequences and injects compressed right-context information. 2
The implementation detail matters. The paper trains on Qwen3-1.7B with 60B tokens of continued pretraining on 32 H100 GPUs. It reports 2.4×-12.9× higher throughput than bidirectional dLLMs and 1.9×-2.9× speedup over autoregressive baselines in batch serving. 2
Technical read
The architecture has two variants that are useful to separate. R2LM jointly trains the causal backbone plus right-to-left Mamba mechanism. R2LM-PI freezes the backbone and trains only the SSM sidecar on 5B tokens, recovering 59% of the joint model's gain. 2
That plug-in result is the reason this paper ranks above several CV papers with venue tags. If the claim survives reproduction, it gives diffusion language modeling a route toward existing LLM serving infrastructure instead of asking operators to abandon KV cache.
3. Qwen-Image-2.0-RL: RLHF becomes a diffusion post-training stack
arXiv: 2606.27608 · Yixian Xu et al. · Alibaba / Qwen Team · cs.CV, cs.LG 3
Why it ranks third
Qwen-Image-2.0-RL is the batch's most complete industry-scale RL post-training report for image diffusion. The Qwen team applies RLHF and on-policy distillation to Qwen-Image-2.0, with task-specific composite reward models built from fine-tuned vision-language models that use chain-of-thought reasoning. 3
The reported gains cover both generation and editing. Qwen-Image-2.0-RL reaches 57.84 on Qwen-Image-Bench, up 2.61 over the base model. It also reports Elo 1193 in the text-to-image arena, up 78, and Elo 1349 in the image-editing arena, up 93. 3
Technical read
The technical contribution is not just "apply GRPO to diffusion." The paper combines a hybrid classifier-free guidance strategy, intra-group reward-range filtering for prompt curation, per-category reward-weight calibration, and trajectory-level velocity matching to consolidate multiple task-specialized policies into one student. 3
Read it if your group is moving from reward modeling to actual generator post-training. The strongest evidence is the complete delta reporting on the Qwen team's own benchmark and arenas. The weaker point is external comparability: the digest evidence does not include independent third-party evaluation or code availability at submission. 3
4. NormGuard: a small penalty for RL-trained flow models
arXiv: 2606.27771 · Tianlin Pan, Lianyu Pang, Cheng Da, Huan Yang, Changqian Yu, Kun Gai, Wenhan Luo · cs.LG, cs.CV 4
Why it ranks fourth
NormGuard is the best diagnostic paper in the set. It studies a failure mode that matters once diffusion and flow-matching generators are optimized against reward models: RL fine-tuning inflates per-step velocity norms by 5%-15% across NFT, AWM, and DPO. 4 The authors argue that inference-time renormalization fails because the inflation is co-adapted into the model weights, not added as a separable sampling artifact. 4
The paper's proposed fix is deliberately small. NormGuard adds a hinge penalty when the learned velocity norm exceeds the reference velocity norm. 4 The paper reports MLLM-judged image-quality win rates of 47%-73% across Qwen3.5 and GPT-4.1 judges, RealScore improvement in 6 of 7 settings, and reward preservation with PickScore changes from -0.003 to +0.011 and HPSv2 changes from -0.004 to +0.001. 7
Technical read
The deeper value is the decomposition: norm inflation appears to drive perceptual artifacts while directional realignment carries most reward gain. The paper supports that view with adjoint sensitivity analysis showing that norm scaling has no coherent first-order reward signal, with a reported noise-to-signal ratio of 3×-100×. 7
Read NormGuard after Qwen-Image-2.0-RL if you care about what can go wrong in reward-optimized generators. The evidence is more diagnostic than architectural, but the result is easier to test: add the penalty, compare reward retention and perceptual quality, and check whether few-step inference improves.
5. Masked Language Flow Models: flow LMs reach reasoning benchmarks
arXiv: 2606.27617 · Iskander Azangulov et al. · University of Oxford · cs.LG 5
Why it ranks fifth
Masked Language Flow Models earns the last slot because it pushes flow-based language modeling into tasks that readers can recognize: GSM8K for math reasoning and MT-Bench for instruction following. The authors describe this as the first time flow-based language models have been scaled to downstream reasoning and instruction-following tasks. 5
The method adapts a 1028M-parameter pretrained masked diffusion model into an MLFM using LoRA adapters, AdaLN conditioning, and a frozen backbone. 5 The code is available at github.com/imbirik/mlfm. 5
Technical read
MLFM combines masking from masked diffusion models with continuous flows through a Brownian bridge stochastic interpolant. Its sampler alternates continuous denoising with discrete unmasking of confident tokens, which lets tokens be promoted adaptively rather than decoded in a fixed left-to-right order. 8
The evidence is promising but less complete than R2LM's serving story. The digest evidence confirms the benchmark targets and model adaptation path, but it does not include the full numeric GSM8K or MT-Bench table. 5 Read it if your main question is whether flow matching can become more than an image-generation training recipe.
Reading order by research area
For pixel-space image generation, start with PixelU. For diffusion language models, read Bifocal dLLMs first if serving efficiency is your bottleneck, then MLFM if you care about reasoning and instruction-following. For RL-trained generators, read Qwen-Image-2.0-RL for the full pipeline and NormGuard for the failure mode that pipeline designers should monitor.
The strongest runner-up is SIFT, an ECCV 2026 video-diffusion paper that trains on model-generated videos to break the reconstruction shortcut in physically plausible motion. 9 SIFT missed the top five mainly because the available abstract-level evidence does not report the quantitative comparison table, while NormGuard and MLFM give clearer signals for researchers deciding what to open first. 9
Cover image: quality-throughput plot from the Bifocal dLLMs HTML paper.
Add more perspectives or context around this Post.