
July 1, 2026 · 8:14 PM
GLM-5.1:智谱把模型能力拉到 8 小时任务里
GLM-5.1 的重点不只是 SWE-Bench Pro 58.4 分,而是把模型放进数百轮工具调用和 8 小时自我改进循环里。文章拆解它的长任务实验、工程优化能力、开源与 API 边界,并指出官方材料里尚未说清的多模态与自评可靠性问题。

GLM-5.1 最值得看的,不是智谱 AI 又把某个榜单分数往上推了一点,而是它把模型能力的评价重心从「一次回答够不够强」挪到「连续干几个小时还会不会变好」。Z.AI 官方博客页标注这次发布为 2026-04-07,称 GLM-5.1 是面向 agentic engineering 的下一代旗舰模型;Hugging Face 模型页则把它和 GLM-5 技术报告、GitHub 仓库、API 文档放在同一组入口里。12
先校正一个容易被标题带偏的点:当前 Z.AI 开发者文档把 GLM-5.1 的输入模态和输出模态都列为 Text。也就是说,公开材料里能明确落地的主线不是图像、音频或视频多模态,而是文本模型在长上下文、工具调用、代码执行和持续优化里的表现。3
这次发布真正想证明什么
GLM-5.1 的核心命题可以压成一句话:模型不能只会「生成代码」,还要能在一个工程任务里反复试错、读日志、改策略、继续跑下去。官方博客把这种能力称为长时程任务能力,强调模型可以在复杂目标下保持执行、测试、修复和交付,而不是在第一次生成后就结束。1
这和过去两年代码模型常见的宣传点不太一样。SWE-Bench、Terminal-Bench 这类榜单仍然重要,但 GLM-5.1 想强调的是「有效运行时间」:给模型更多轮次、更多工具调用、更多反馈之后,它还能不能持续找到新改进,而不是在前几十轮把熟悉套路用完就停住。
从模型卡看,GLM-5.1 权重已经在 Hugging Face 公开,页面标注模型规模为 754B parameters,张量类型包含 BF16 和 F32;官方博客也说明 GLM-5.1 以 MIT License 开源,并可通过 api.z.ai、BigModel.cn 以及本地部署路径使用。21
榜单怎么读:代码强,但不是每项都赢
官方表格里,GLM-5.1 的强项集中在复杂软件工程和 Agent 任务。下面几项最能说明它的定位:
| 指标 | 官方给出的 GLM-5.1 结果 | 更应该怎么读 |
|---|---|---|
| SWE-Bench Pro | 58.4,官方表格中高于 GPT-5.4 的 57.7、Claude Opus 4.6 的 57.3、Gemini 3.1 Pro 的 54.2。1 | 这是它最醒目的软件工程成绩,说明它在复杂代码修复上有竞争力;但脚注也显示评测使用 OpenHands 和定制 prompt,不能脱离 harness 横向外推。 |
| NL2Repo | 42.7,高于 GLM-5 的 35.9,但低于 Claude Opus 4.6 的 49.8。1 | 仓库生成能力进步明显,但仍不是表格里最强。 |
| Terminal-Bench 2.0 Terminus-2 | 63.5,高于 GLM-5 的 56.2,低于 Gemini 3.1 Pro 的 68.5 和 Claude Opus 4.6 的 65.4。1 | 终端真实任务有提升,但竞争格局还很紧。 |
| CyberGym | 68.7,高于 GLM-5 的 48.3,也高于表中 Claude Opus 4.6 的 66.6 和 GPT-5.4 的 66.3。1 | 安全任务分数很高,但脚注说明不同模型使用不同 CLI / harness,且部分模型会因安全风险拒答,读数要看评测设置。 |
如果只看这些分数,GLM-5.1 像一次强代码模型更新;如果把后面的长任务实验一起看,它更像智谱在回答另一个问题:当模型被放进「跑实验—看结果—改方案」的循环里,它能不能自己把工作推进下去。
三个长任务实验,重点在「后半程」
官方博客给了三个逐步降低反馈结构化程度的实验:向量数据库优化、GPU kernel 优化、8 小时网页桌面构建。它们共同测试的不是第一版能写多漂亮,而是模型过了几十轮之后还会不会有新主意。
第一个实验是 VectorDBBench。任务给模型一个 Rust 骨架和空实现,让它实现近似最近邻搜索服务;最终用 SIFT-1M 数据集评测,在 Recall ≥ 95% 的约束下看 QPS。官方说,原 50-turn 设定下此前最好结果是 Claude Opus 4.6 的 3,547 QPS。1
智谱把它改成外层优化循环:每次迭代里,模型可以编辑代码、编译、测试、profile,然后自主决定何时提交新版本。GLM-5.1 最终跑到 655 次迭代、6,000+ 次工具调用,达到 21.5k QPS,约为原 50-turn 最好结果的 6 倍。它并不是一路线性变好,而是在第 90 轮附近从全量扫描转向 IVF cluster probing 加 f16 压缩,在第 240 轮附近引入 u8 prescoring 加 f16 reranking 的两阶段流程。1
这段最有信息量。因为它显示模型不仅会调参数,还能在读到瓶颈之后换结构。对工程 Agent 来说,这比「一次生成一段能跑的代码」更接近真实工作:一开始的方案通常不够好,关键是能不能从失败日志里爬出来。
第二个实验是 KernelBench Level 3。KernelBench 要求模型把参考 PyTorch 实现改写成更快的 GPU kernel,同时保持输出一致;Level 3 覆盖 MobileNet、VGG、MiniGPT、Mamba 等完整架构,共 50 个问题。官方给出的基线是 torch.compile 默认设置 1.15×,max-autotune 1.49×。1
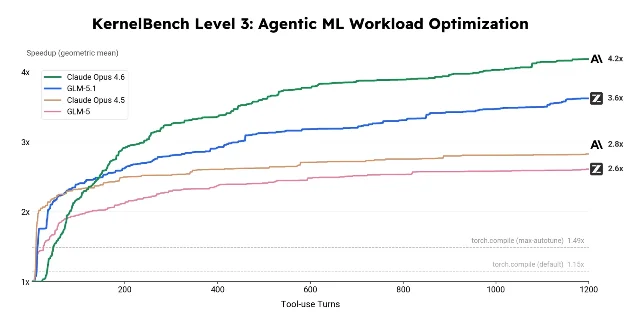
在这个实验里,GLM-5.1 最终达到 3.6× 几何平均加速,高于 GLM-5 和 Claude Opus 4.5;Claude Opus 4.6 仍以 4.2× 领先。官方脚注也给了约束:50 个问题分别在带一张 H100 GPU 的隔离 Docker 容器中运行,每题最多 1200 个 tool-use turns,正确性和性能分开评估,且用 Claude Opus 4.6 与 GPT-5.4 审计是否存在 benchmark exploitation。1
这说明 GLM-5.1 的长轮次优化不是空口说「耐心更好」,但也说明它还没压过最强对手。更准确的读法是:智谱把可持续优化能力从「论文里的概念」推到了可复核的工程类任务上,但在最硬的 GPU kernel 优化里,第一梯队之间仍有差距。
第三个实验是 8 小时构建 Linux 风格浏览器桌面。官方设置里没有 starter code、没有设计稿、没有中间指导,只给一个自然语言需求;模型被放进一个自评循环,每轮执行后复盘缺什么、哪里粗糙、交互哪里坏了,再继续迭代。1
这个案例更像产品 demo,而不是严格 benchmark。它的价值在于说明 GLM-5.1 面向的是「主观质量也要持续改」的任务,比如前端原型、复杂文档、系统搭建。它的局限也在这里:没有单一数值目标时,模型自评到底靠不靠谱,会直接决定后半程是在改进,还是在自我感觉良好地打磨边角。
技术报告能解释部分路线,但别把它等同于 5.1 配方
Hugging Face 模型页把 GLM-5.1 和 GLM-5 技术报告连在一起;arXiv 页面显示这篇报告题为《GLM-5: from Vibe Coding to Agentic Engineering》,v1 提交于 2026-02-17,v2 修订于 2026-02-24。24
这份技术报告可以解释 GLM-5 系列为什么会往长时程 Agent 方向走。摘要里提到,GLM-5 采用 DSA 来降低训练和推理成本,同时保持长上下文能力;后训练部分使用新的异步强化学习基础设施,把生成和训练解耦;报告还提出异步 Agent RL 算法,用来提升模型从复杂、长时程交互中学习的质量。4
但要注意,GLM-5.1 发布页并没有完整披露「从 GLM-5 到 GLM-5.1」的增量训练配方。把 DSA、异步 RL 和 5.1 的每个分数直接画等号,会超出公开材料。更稳妥的说法是:GLM-5 技术报告解释了这个系列的技术方向,GLM-5.1 的博客和模型卡展示了这一方向在代码 Agent 和长任务上的最新结果。
开发者该看哪些落地点
如果你想把 GLM-5.1 接进编码 Agent,最直接的入口不是聊天页面,而是 API 和本地推理。Z.AI 开发者文档列出了 200K context length、128K maximum output tokens,并说明模型支持 thinking mode、streaming output、function call、context caching、structured output 和 MCP。3
本地部署方面,Hugging Face 模型卡列出 SGLang、vLLM、xLLM、Transformers、KTransformers 等框架支持,并给出对应 cookbook、recipes 或文档入口。2 这对开源模型很关键,但 754B 的规模也意味着「可下载」和「普通团队可经济地跑满」不是一回事。真正要落地,还要看量化方案、显存预算、吞吐、上下文缓存成本和工具调用框架的稳定性。
API 侧,Z.AI 文档给出的示例请求使用
model: "glm-5.1",可以打开 thinking,也可以用 OpenAI SDK 兼容方式调用 Z.AI base URL。3 官方博客还说 GLM-5.1 兼容 Claude Code 和 OpenClaw,并面向 Coding Plan 用户滚动开放;峰时和非峰时 quota 消耗不同,限时促销期另算。1这决定了它的第一批适用场景:不是随手问答,而是愿意让模型连续跑、能给它测试环境、日志和工具权限的工程团队。没有这些外部反馈,GLM-5.1 的长时程优势很难显出来。
仍然要打问号的地方
第二,长任务的成本。VectorDBBench 的 655 次迭代、KernelBench 的最多 1200 个 tool-use turns、Terminal-Bench 的 3 小时 timeout,本质上都在消耗时间、算力和上下文预算。官方 benchmark 证明「多跑有用」,但生产环境还要回答「多跑值不值」。1
第三,自评可靠性。带明确指标的任务可以用 QPS、speedup 或测试通过率纠偏;网页桌面这类开放任务只能靠模型自己判断还差什么。官方博客也承认,长时程优化仍面临逃离局部最优、维持数千次工具调用跨度内的一致性、以及在没有数值指标时发展可靠自评的问题。1
所以,GLM-5.1 对读者的意义不是「又一个最强模型」。更具体的判断是:如果你的任务可以被拆成可运行、可测试、可反复改进的工程循环,GLM-5.1 值得进入候选清单;如果你的任务只是短对话、内容生成或没有反馈环境的泛办公,榜单分数不会自动转化成实际收益。
下一步最该看的,不是它能不能再刷高一个 benchmark,而是第三方能否复现它在长轮次任务中的后半程收益:同样给几百轮、几千次工具调用,GLM-5.1 是否仍能稳定换策略、修错误、保约束,并在成本上说得通。
Add more perspectives or context around this Post.